

What is Python?
Python is the most used high-level was developed by Guido van Rossum and released first on February 20, 1991, It is interpreted programming language known for its readability and clear syntax. It provides various libraries and frameworks that simplify machine learning development.
Python’s versatility and active community make it an ideal language for machine-learning projects and supports object-oriented programming, most commonly used to perform general-purpose programming. Python is used in several domains like Data Science, Machine Learning, Deep Learning, Artificial Intelligence, Networking, Game Development, Web Development, Web Scraping, and various other domains.

What is Machine Learning?
Machine Learning is the field of study that gives computers the capability to learn without being explicitly programmed. ML is one of the most exciting technologies that one has ever come across. As it is evident from the name, it gives the computer something that makes it more similar to humans: The ability to learn. Machine learning is actively being used today, perhaps in many more places than one would expect.
Definition of Machine Learning
Machine learning is a subset of artificial intelligence that enables computer systems to learn from data and improve their performance without being explicitly programmed. It involves training algorithms using data to build models that can make predictions, recognize patterns, or classify objects.
The goal of machine learning is to develop systems that can adapt and generalize from data, providing solutions to complex problems across various domains.
its simplicity, versatility, and extensive library support. Today, Python is considered one of the primary languages for machine learning and artificial intelligence research and development.
Python’s Role in Machine Learning
Python has a crucial role in machine learning because Python provides libraries like NumPy, Pandas, Scikit-learn, TensorFlow, and Keras. These libraries offer tools and functions essential for data manipulation, analysis, and building machine learning models. It is well-known for its readability and offers platform independence. These all things make it the perfect language of choice for Machine Learning.
Why do we need Machine Learning?
Machine Learning today has all the attention it needs. Machine Learning can automate many tasks, especially the ones that only humans can perform with their innate intelligence. Replicating this intelligence to machines can be achieved only with the help of machine learning.
With the help of Machine Learning, businesses can automate routine tasks. It also helps in automating and quickly create models for data analysis. Various industries depend on vast quantities of data to optimize their operations and make intelligent decisions. Machine Learning helps in creating models that can process and analyze large amounts of complex data to deliver accurate results. These models are precise and scalable and function with less turnaround time. By building such precise Machine Learning models, businesses can leverage profitable opportunities and avoid unknown risks.

ADVANTAGES AND DISADVANTAGES OF PYTHON IN MACHINE LEARNING
The answer is more complicated than a simple yes or no.
In many ways, Python is not the ideal tool for the job. In nearly every
instance, the data that machine learning is used for is massive. Python’s lower speed means it can’t handle enormous volumes of data fast enough for a professional setting.
Machine learning is a subset of data science, and Python was not designed with data science in mind.
However, Python’s greatest strength is its versatility. There are hundreds of libraries available with a simple download, each of which allow developers to adapt their code to nearly any problem.
While vanilla Python is not especially adapted to machine learning, it can be very easily modified to make writing machine learning algorithms much simpler.
History of machine learning and its relation to python

Machine learning has a rich history that spans several decades, and its development has been closely tied to advancements in computing and technology. Here’s a brief overview of the history of machine learning and its relationship with Python:
1. 1950s – 1960s: Early Concepts and Foundations:
- The foundations of machine learning were laid with the work of researchers such as Alan Turing and Marvin Minsky. Early concepts like the perceptron were introduced during this
2. 1970s – 1980s: AI Winter and Rule-Based Systems:
- The field faced skepticism and funding challenges during the “AI winter.” Rule- based expert systems became popular as a way to approach artificial
3. 1990s: Emergence of Neural Networks:
- Neural networks gained attention, with the backpropagation algorithm proving to be a crucial However, computing power limitations hampered the training of large neural networks.
4. Late 1990s – Early 2000s: Support Vector Machines and Boosting:
- Support Vector Machines (SVM) and boosting algorithms gained popularity as powerful machine learning techniques. These methods were widely used in various applications, including image recognition and natural language
5. Mid-2000s: Rise of Big Data and Python’s Emergence:
- The explosion of big data highlighted the limitations of traditional machine learning algorithms. Around the same time, Python gained popularity as a programming language due to its simplicity and
6. 2010s: Deep Learning and Python Dominance:
- Deep learning, particularly deep neural networks, gained prominence with breakthroughs in image and speech recognition. Frameworks like TensorFlow and PyTorch, both of which are primarily Python-based, played a crucial role in popularizing deep
7. Present: Python as the Dominant Language:
- Python has become the de facto language for machine learning and data Its extensive libraries and frameworks, including NumPy, SciPy, scikit- learn, and the aforementioned TensorFlow and PyTorch, have made it the preferred choice for researchers and practitioners in the field.
8. Future Trends: Continued Integration and Ethical Considerations:
- The integration of machine learning into various industries is expected to continue, with a focus on interpretability, fairness, and ethics. Continued advancements in hardware, algorithms, and interdisciplinary collaborations are likely to shape the future of machine learning.
Python’s popularity in the field of machine learning can be attributed to several factors:
1.Ease of Learning and Readability:
- Python is known for its simple and readable syntax, making it easy for beginners to learn and This is crucial for the machine learning community, which includes both experts and those new to the field.
2. Extensive Libraries and Frameworks:
- Python boasts a rich ecosystem of libraries and frameworks that are specifically designed for machine learning and data Some of the most popular ones include:
- NumPy and pandas: For numerical and data
- Scikit-learn: For classical machine learning
- TensorFlow and PyTorch: Deep learning frameworks that have gained widespread
- Keras A high-level neural networks API that can run on top of TensorFlow or Theano
- Matplotlib and Seaborn: For data
3. Community Support:
- Python has a large and active community, which means that developers have access to a wealth of resources, tutorials, and forums for support. This community-driven nature contributes to the rapid development and improvement of machine learning tools and
4. Flexibility and Versatility:
- Python is a versatile language that can be used for a wide range of Its flexibility allows researchers and developers to seamlessly integrate machine learning into existing workflows or applications.
5. Open Source:
- Python and many of its machine learning libraries are open This means that anyone can view, modify, and distribute the source code, fostering collaboration and innovation within the community.
6. Integration with Other Technologies
- Python can easily integrate with other technologies and tools commonly used in the data science and machine learning ecosystem, such as databases, big data technologies (e.g., Apache Spark), and web
7. Industry Adoption:
- Many companies and organizations have adopted Python as their primary language for machine learning and data This industry adoption has further fueled the popularity of Python in these domains.
8. Job Market and Career Opportunities:
- The demand for professionals with expertise in machine learning and Python is high. Learning Python can open up numerous career opportunities in the rapidly growing field of artificial intelligence.
Getting started with python for machine learning

1. Install Python:
Make sure you have Python installed on your machine. You can download the latest version from the official Python website.
2. Choose an Integrated Development Environment (IDE):
Select an IDE to write and run your Python code. Some popular choices for machine learning include Jupyter Notebooks, VSCode, and PyCharm. Jupyter Notebooks are particularly popular for data exploration and visualization.
3. Install Necessary Libraries:
Python has several powerful libraries for machine learning. You’ll commonly use:
- NumPy: For numerical
- Pandas: For data manipulation and
- Matplotlib and Seaborn: For data
- Scikit-learn: For machine learning algorithms and
- TensorFlow or PyTorch: For deep
You can install these libraries using the following command in your terminal or command prompt:
bashCopy code
pip install numpy pandas matplotlib seaborn scikit-learn tensorflow
4. Learn the Basics of Python:
Familiarize yourself with basic Python concepts such as variables, data types, control structures (if statements, loops), functions, and error handling. There are plenty of online tutorials and resources to help you with this.
5. Understand NumPy and Pandas:
NumPy and Pandas are fundamental for data manipulation. Learn about arrays, matrices, data frames, and basic operations in these libraries.
6. Explore Data Visualization:
Matplotlib and Seaborn are widely used for data visualization. Learn how to create various types of plots to understand your data better.
7. Dive into Scikit-learn:
Scikit-learn provides a wide range of machine learning algorithms and tools. Start with simple models like linear regression and gradually move on to more complex ones like decision trees and support vector machines.
8. Learn about TensorFlow or PyTorch:
If you’re interested in deep learning, choose either TensorFlow or PyTorch. Both have extensive documentation and tutorials. Start with simple neural networks and gradually explore more advanced architectures.
9. Work on Real Projects:
Apply what you’ve learned by working on real projects. Kaggle is a great platform where you can find datasets and participate in competitions to enhance your skills.
10. Stay Updated:
The field of machine learning is dynamic. Follow blogs, research papers, and communities like Stack Overflow, Reddit, or specialized forums to stay updated on the latest developments.
Machine Learning Algorithms in Python
- Linear regression
- Decision tree
- Logistic regression
- Support Vector Machines (SVM)
- Naive Bayes
Which are the 5 most used machine learning algorithms?
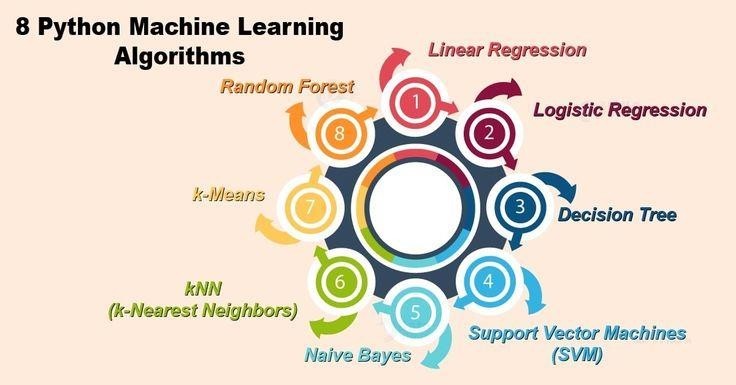
1. Linear regression
It is one of the most popular Supervised Python Machine Learning algorithms that maintains an observation of continuous features and based on it, predicts an outcome. It establishes a relationship between dependent and independent variables by fitting a best line. This best fit line is represented by a linear equation Y=a*X+b, commonly called the regression line.
In this equation,
Y – Dependent variable a- Slope
X – Independent variable b- Intercept
The regression line is the line that fits best in the equation to supply a relationship between the dependent and independent variables. When it runs on a single variable or feature, we call it simple linear regression and when it runs on different variables, we call it multiple linear regression. This is often used to estimate the cost of houses, total sales or total number of calls based on continuous variables.
2. Decision Trees
A decision tree is built by repeatedly asking questions to the partition data. The aim of the decision tree algorithm is to increase the predictiveness at each level of partitioning so that the model is always updated with information about the dataset.
Even though it is a Supervised Machine Learning algorithm, it is used mainly
for classification rather than regression. In a nutshell, the model takes a particular instance, traverses the decision tree by comparing important features with a conditional statement. As it descends to the left child branch or right child branch of the tree, depending on the result, the features that are more important are closer to the root. The good part about this machine learning algorithm is that it works on both continuous dependent and categorical variables.
3. Logistic regression
A supervised machine learning algorithm in Python that is used in estimating discrete values in binary, e.g: 0/1, yes/no, true/false. This is based on a set of independent variables. This algorithm is used to predict the probability of an event’s occurrence by fitting that data into a logistic curve or logistic function. This is why it is also called logistic regression.
Logistic regression, also called as Sigmoid function, takes in any real valued number and then maps it to a value that falls between 0 and 1. This algorithm finds its use in finding spam emails, website or ad click predictions and customer churn. Check out this Prediction project using python.
Sigmoid Function is defined as,
f(x) = L / 1+e^(-x)
x: domain of real numbers L: curve’s max value
4. Support Vector Machines (SVM)
This is one of the most important machine learning algorithms in Python which is mainly used for classification but can also be used for regression tasks. In this algorithm, each data item is plotted as a point in n-dimensional space, where n denotes the number of features you have, with the value of each feature as the value of a particular coordinate.
SVM does the distinction of these classes by a decision boundary. For e.g: If length and width are used to classify different cells, their observations are plotted in a 2D space and a line serves the purpose of a decision boundary. If you use 3 features, your decision boundary is a plane in a 3D space. SVM is highly effective in cases where the number of dimensions exceeds the number of samples.
5. Naive Bayes
Naive Bayes is a supervised machine learning algorithm used for classification tasks. This is one of the reasons it is also called a Naive Bayes Classifier. It assumes that features are independent of one another and there exists no correlation between them. But as these assumptions hold no truth in real life, this algorithm is called ‘naive’.
This algorithm works on Bayes’ theorem which is:
p(A|B) = p(A) . p(B|A) / p(B)
In this,
p(A): Probability of event A p(B): Probability of event B
p(A|B): Probability of event A given event B has already occurred p(B|A): Probability of event B given event A has already occurred
The Naive bayes classifier calculates the probability of a class in a given set of features, p( yi I x1, x2, x3,…xn). As this is put into the Bayes’ theorem, we get :
p( yi I x1, x2…xn)= p(x1,x2,…xn I yi). p(yi) / p(x1, x2….xn)
As the Naive Bayes’ algorithm assumes that features are independent, p( x1, x2…xn I yi) can be written as :
p(x1, x2,….xn I yi) = p(x1 I yi) . p(x2 I yi)…p(xn I yi)
p(x1 I yi) is the conditional probability for a single feature and can be easily estimated from the data. Let’s say there are 5 classes and 10 features, 50 probability distributions need to be stored. Adding all these, it becomes easier to calculate the probability to observe a class given the values of features (p(yi I x1,x2,…xn)).
Python Machine Learning Best Practices and Techniques
In this section, we will explore some best practices and techniques that can help you improve the performance of your machine learning models, optimize your code, and ensure the success of your Python ML projects.
Data Preprocessing and Feature Engineering
Data preprocessing and feature engineering play a crucial role in the success of your machine learning models. Some common preprocessing steps and techniques include:
- Handling missing data: Use techniques like imputation, interpolation, or deletion to handle missing data in your
- Feature scaling: Standardize or normalize your features to ensure that they are on the same scale, as some algorithms are sensitive to the scale of input features.
- Categorical data encoding: Convert categorical data into numerical format using techniques like one-hot encoding or label
- Feature selection: Identify and select the most important features that contribute to the target variable using techniques like recursive feature elimination, feature importance from tree-based models, or correlation
- Feature transformation: Apply transformations like log, square root, or power to your features to improve their distribution or relationship with the target variable.
Model Evaluation and Validation
Proper model evaluation and validation are essential to ensure the reliability and generalization of your machine learning models. Some best practices include:
- Train-test split: Split your dataset into separate training and testing sets to evaluate the performance of your model on unseen
- Cross-validation: Use techniques like k-fold cross-validation to train and test your model on different subsets of the data, reducing the risk of
- Performance metrics: Choose appropriate performance metrics, such as accuracy, precision, recall, F1-score, or mean squared error, depending on your problem
- Learning curves: Analyze learning curves to diagnose issues like underfitting, overfitting, or insufficient training
Hyperparameter Tuning
Hyperparameter tuning is the process of finding the optimal set of hyperparameters for your machine learning models. Some techniques for hyperparameter tuning include:
- Grid search: Perform an exhaustive search over a specified range of hyperparameter values to find the best
- Random search: Sample random combinations of hyperparameter values from a specified range to find the best
- Bayesian optimization: Use a probabilistic model to select the most promising hyperparameter values based on previous
Efficient Python Code for Machine Learning
Writing efficient Python code can significantly improve the performance of your machine learning projects. Some tips for writing efficient code include:
- Use vectorized operations: When working with NumPy arrays or pandas DataFrames, use vectorized operations instead of loops for better
- Utilize efficient data structures: Choose appropriate data structures like lists, dictionaries, or sets to optimize the performance of your
- Parallelize computations: Use libraries like joblib or Dask to parallelize your computations and take advantage of multi-core processors.
- Profiling and optimization: Use profiling tools like cProfile or Py-Spy to identify performance bottlenecks in your code and optimize them
By following these best practices and techniques, you can improve the performance of your machine learning models, optimize your Python code, and ensure the success of your ML projects. Continuously learning and staying updated with the latest advancements in the field will further enhance your skills and contribute to your growth as a machine learning practitioner.
- Python is widely used for machine learning projects and applications across various domains. Here’s an example of a real-world Python machine learning project:
Project Title: Predictive Maintenance for Industrial Equipment
Objective: Develop a machine learning model to predict equipment failures in an industrial setting, enabling proactive maintenance and minimizing downtime.
Steps and Components:
- Data Collection:
- Gather historical data from sensors attached to industrial equipment, including temperature, pressure, vibration, and other relevant parameters.
- Collect information on past equipment failures, maintenance records, and environmental
2. Data Preprocessing:
- Clean and preprocess the data, handling missing values and
- Normalize or scale numerical
- Engineer new features, such as rolling averages or time-based
3. Feature Selection:
- Identify the most important features for predicting equipment
- Use techniques like feature importance from tree-based models or correlation
4. Model Selection:
- Choose appropriate machine learning algorithms for classification, such as Random Forests, Support Vector Machines, or Neural
- Experiment with different models and hyperparameter tuning for optimal performance.
5. Training and Validation:
- Split the data into training and validation
- Train the machine learning model on historical data and validate its performance on a separate
6. Model Evaluation:
- Evaluate the model’s performance using metrics like precision, recall, F1 score, and area under the ROC
- Use confusion matrices to understand false positives and false
7. Deployment:
- Deploy the trained model to a production environment, integrating it with the existing infrastructure.
- Implement a system for real-time prediction or batch processing, depending on the
8. Monitoring and Maintenance:
- Set up monitoring to track the model’s performance over
- Implement a feedback loop to continuously update the model based on new data and improve its accuracy.
9. Integration with Maintenance Workflow:
- Integrate the predictive maintenance system with the organization’s maintenance
- Generate alerts or work orders for maintenance personnel when the model predicts an imminent
10. Documentation:
- Document the entire process, from data collection to deployment, for future reference and collaboration.
This project showcases the application of machine learning in a practical setting, helping businesses optimize their maintenance processes and reduce operational costs.
Resources to Learn Python Machine Learning and AI
In this final section, we will provide a list of resources that can help you learn and master Python machine learning and AI. These resources cover different aspects of machine learning, such as algorithms, tools, libraries, and real- world applications, catering to various learning preferences and skill levels.
1. Books
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron.
- “Python Machine Learning” by Sebastian Raschka and Vahid
- “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron
2. Online Courses:
Coursera:
- Machine Learning by Andrew Ng
- Deep Learning Specialization by Andrew Ng
edX:
- Microsoft Professional Program in Artificial Intelligence
- Udacity:
- Intro to Machine Learning with PyTorch and TensorFlow
3. Websites and Documentation:
- Scikit-learn Documentation
- TensorFlow Documentation
- PyTorch Documentation
4. Tutorials and Blogs:
- Towards Data Science on
- Analytics Vidhya – A community of data
- Kaggle Kernels – Learn from and share code on real-world datasets.
5. YouTube Channels:
- sentdex – Python programming and machine learning
- Corey Schafer – Python tutorials with a focus on practical
- 3Blue1Brown – Excellent visualizations explaining mathematical concepts behind machine learning.
6. Practice Platforms:
- Kaggle – Compete in machine learning competitions and explore
- Hackerrank – Artificial Intelligence – Practice AI challenges in
7. Community Forums:
- Stack Overflow – Ask and answer programming questions.
- Reddit – r/MachineLearning – Discussion on machine learning
8. GitHub Repositories:
- Scikit-learn GitHub Repository
- TensorFlow GitHub Repository
- PyTorch GitHub Repository
Conclusion
In conclusion, the journey through machine learning concepts using Python reveals the profound impact this dynamic field has on reshaping our approach to problem-solving and decision-making. Python, with its rich ecosystem of libraries such as TensorFlow, scikit-learn, and PyTorch, empowers developers and data scientists to harness the potential of machine learning.
From understanding the fundamentals of supervised and unsupervised learning to delving into advanced techniques like deep learning and reinforcement learning, the Python ecosystem provides a versatile platform for exploring the vast landscape of machine learning. The ability to preprocess and analyze data, build robust models, and evaluate their performance has become more accessible, thanks to Python’s intuitive syntax and the wealth of community-driven resources.
As we navigate the intricacies of algorithms, feature engineering, and model optimization, it becomes evident that machine learning is not merely a technical pursuit but a creative process that demands thoughtful consideration of data, problem formulation, and algorithmic choices. Python’s flexibility and readability contribute significantly to the iterative nature of model development, allowing practitioners to experiment and refine their approaches seamlessly.


